
This is part 2 of our Building Recce Cloud series: Part 1: The Adoption Problem | Part 2: Eliminating the Setup Barrier | Part 3: Guided Data Review | Part 4: AI Data Reviews
Data teams kept telling us 'this is exactly what we need', then churning two weeks later. The problem wasn't the product. It was asking users to set up CI/CD before they could see any value.
In our previous article, we discovered that data teams loved Recce's concept but struggled with adoption. The question became: what if they could experience Recce's value in under two minutes? We knew we needed to flip from "setup first" to "value first", but how do we actually build that?
Moving from System Requirements to Value Delivery
Instead of asking "what does our system require," we asked "what do data teams care about most? And how quickly can we get them to that value?" This shift led us to completely rethink our approach through a systematic three-step process.
Step 1: User Research Revealed the Value-First Need
We mapped what data teams care about doing in Recce to what behind the scenes setup is necessary. In other words, it was designing the user's journey through increasing value, not just feature planning.
For Recce to work, we need to compare two environments. The most common case is comparing your development branch against your production or main branch to see what your changes will impact. We can start by collecting metadata from both environments and use that for comparison and impact analysis.
What Data Teams Value at Each Level
Metadata diffing to view what changed and impact:
- ✅ Setup needed: Provide production and development metadata for comparison
- ❌ Without this setup: View changes and impact using sample data only
Data-diffing between production and development models
- ✅ Setup needed: Connect data warehouse
- ❌ Without this setup: Metadata diffing only
Easily open sessions based on live pull requests (PR), github events, repo mapping
- ✅ Setup needed: Connect Github repo
- ❌ Without this setup: No automatic PR tracking
Automating metadata uploads and triggering tests at pull requests
- ✅ Setup needed: Setup CI/CD (Continuous Integration / Continuous Delivery)
- ❌ Without this setup: Manual uploads and PR management
Our Value-First Adoption Vision
From this research, we designed the adoption path around increasing value at each step:
- Immediate exploration: Data teams sign up and immediately can explore a validation workflow using our sample data. No uploads nor configuration needed to see what changes and downstream impacts look like in Recce.
- Lineage impact: When they want to see changes with their own work, they can upload their production and development metadata. They can understand the impact radius of their code changes on models and metrics.
- Data impact: Connecting their data warehouse unlocks actual data queries and data-diffing. This unlocks the ability to validate the changes they care most about.
- Team workflow: Connecting GitHub provides the PR-focused validation workflow they need most, during code reviews. They now have a way of systemically validating each other's logic changes.
- Automated workflow: CI/CD integration makes everything hands-free: metadata uploads, session creation, and custom data checks happen automatically on every PR.
 Value-first adoption journey
Value-first adoption journey
Each step would deliver immediate value before asking for more setup. Data teams experience what they gain, then decide if they want the next level of capability.
But when we tried to design this experience, we hit a wall. The problem wasn't UX design, it was our backend architecture.
Step 2: The Technical Reality That Blocked Us
We mentioned in step 1 that Recce needs two environments to provide metadata diffing and data diffing. We used to use a monolithic state file contained everything: environment artifacts (dbt's manifest.json and catalog.json from both main and PR/dev branches), plus session management (checks, runs, runtime info). It causes an issue that users had to manually prepare multiple documents for each time they wanted to use Recce.

Launch with state file
What Users Were Actually Doing
When data engineers started using Recce open source, they would manually prepare both environments locally and successfully launch Recce several times. After seeing the value, they wanted to automate the tedious setup process.
Most data engineers either gave up due to complexity or figured out automation scripts(example-only to show the concept) like this for their CI/CD (Continuous Integration / Continuous Delivery):
1. For production baseline/CD: prepare production metadata
- name: Get Production Artifacts
run: |
dbt deps
dbt build
dbt docs generate
- name: Upload DBT Artifacts
uses: actions/upload-artifact@v4
- name: Prepare dbt Base environment
runs: | ....
- name: Prepare dbt Current environment
runs: | ....
- name: Generate Development Artifacts
runs: | ....
- name: Run Recce CI
run: |
recce run
- name: Upload Recce State File
uses: actions/upload-artifact@v4
The Fundamental Burden That Killed Our Value-First Vision
Though CI/CD achieved automation, the fundamental burden remained: managing artifacts and environments. Production metadata already existed from CD, but every validation run still add on 10+ minute to download those artifacts, configure both production and development environments, and orchestrate everything into a state file.
Faced with this constraint, analytics engineers made a rational choice. They naturally prioritized automating PR validation first because code review is where they catch the most critical issues, yet they lacked systematic tools for data validation during this crucial step. Given the setup burden, they focused their automation efforts where they'd get the highest return.
Once data teams moved validation to CI to avoid the local burden, automation pushed data validation entirely into PR time. Analytics engineers got systematic validation for their highest-value workflow, but lost the ability to validate during active development when fixes are quick and context is fresh.
Step 3: How Sessions Architecture Unlocked Value-First Adoption
A Simple Realization that Led Us to Reengineer our Backend
Looking at the automation scripts, we realized data teams were duplicating work that already existed. Production deployments already run dbt run and dbt docs generate to create current production metadata. Why force every validation download, configure, and orchestrate when production metadata already exists? We just need to make it accessible and let validations use it directly. *
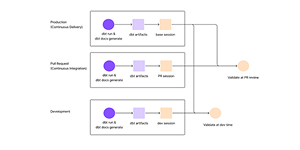
This realization led us to split production and development artifacts into two separate sessions:
- Base session: Production metadata already generated by data teams’ existing deployment pipeline.
- Current session: Development metadata that generated from PR/dev branch is the only part that actually needs generating.
Each session contains dbt's manifest.json (model definitions) and catalog.json (data catalog) that teams already create. State files now focus purely on session management (checks, runs, runtime info) that get generated after Recce launches, not prepared beforehand.

Launch with two sessions
How Sessions Directly Enabled Our Value-First Vision
The sessions architecture eliminated the complexity that was blocking fast adoption. Data teams gain two major benefits:
1. No more artifact orchestration burden Instead of downloading production artifacts, configuring dual environments, and orchestrating state files for every validation, data teams add simple automation:
For production baseline/CD :
- name: Update production metadata
uses: DataRecce/recce-cloud-cicd-action@v0.1
For CI validation (automated per PR):
- name: Update PR metadata
uses: DataRecce/recce-cloud-cicd-action@v0.1
For local development:
No script needed. Since the base session exists in the cloud from their existing deployment process, developers can validate anytime during development without environment preparation.
2. Update once, apply everywhere When the base session updates, all PRs and development environments automatically sync to the latest production metadata.
Complete Unlocks Value-First Adoption + Shift-Left Validation
Now our value-first adoption journey actually works:
- Immediate exploration: Sample data validation - ✅ Try Cloud Immediately
- Personal validation: Upload metadata once - ✅ No unnecessary environment prep
- Deeper investigation: Connect warehouse - ✅ Builds on existing sessions
- Team workflow: GitHub integration - ✅ Leverages automated base sessions
- Automated workflow: CI/CD - ✅ Simple automation, no script complexity
Plus, this architecture restores the validation workflow data teams actually want:
- Testing changes during development: Current session locally vs. automated base in cloud
- Reviewing changes before merging: PR session vs. automated base
Data engineers save the 10+ minutes of repeated environment generation and embrace shift left validation, catching data issues earlier instead of waiting for PR review when fixes are more expensive.

Validate at PR review and dev time
Understanding User Value Transformed Our Architecture
Starting with user value revealed our technical architecture as the barrier to adoption. The shift was letting user research drive technical decisions: when we understood what data teams needed, we knew exactly which constraints to eliminate. Sessions architecture wasn't a technical redesign for its own sake; it was the solution that made value-first adoption possible.
The technical change finally let us build what user research told us: a validation experience that starts with immediate value instead of setup complexity. Data teams can now explore validation with sample data, update to view changes in their own data..etc. No local setup. No complex scripts. No CI/CD expertise required upfront.
We're still learning & want to hear from you:
- What's your biggest barrier to trying new data validation tools? Setup complexity, unclear value, or something else entirely?
- How do you currently handle data change validation? Systematic approach or ad-hoc checking when things break?
This user-first approach continues to drive our product development. Once data teams can easily launch Recce, the next question becomes: "Now that I can validate, what should I actually be validating?" That's the next challenge we're tackling.
Our setup guides have been updated to reflect this sessions-based architecture. Ready to do data validation in action? Try Recce Cloud
