

A dbt pull request shows code changes. It does not show downstream impact, row count shifts, or schema breaks. Recce’s AI-powered summary addresses this gap. Given an active PR, it produces output like this: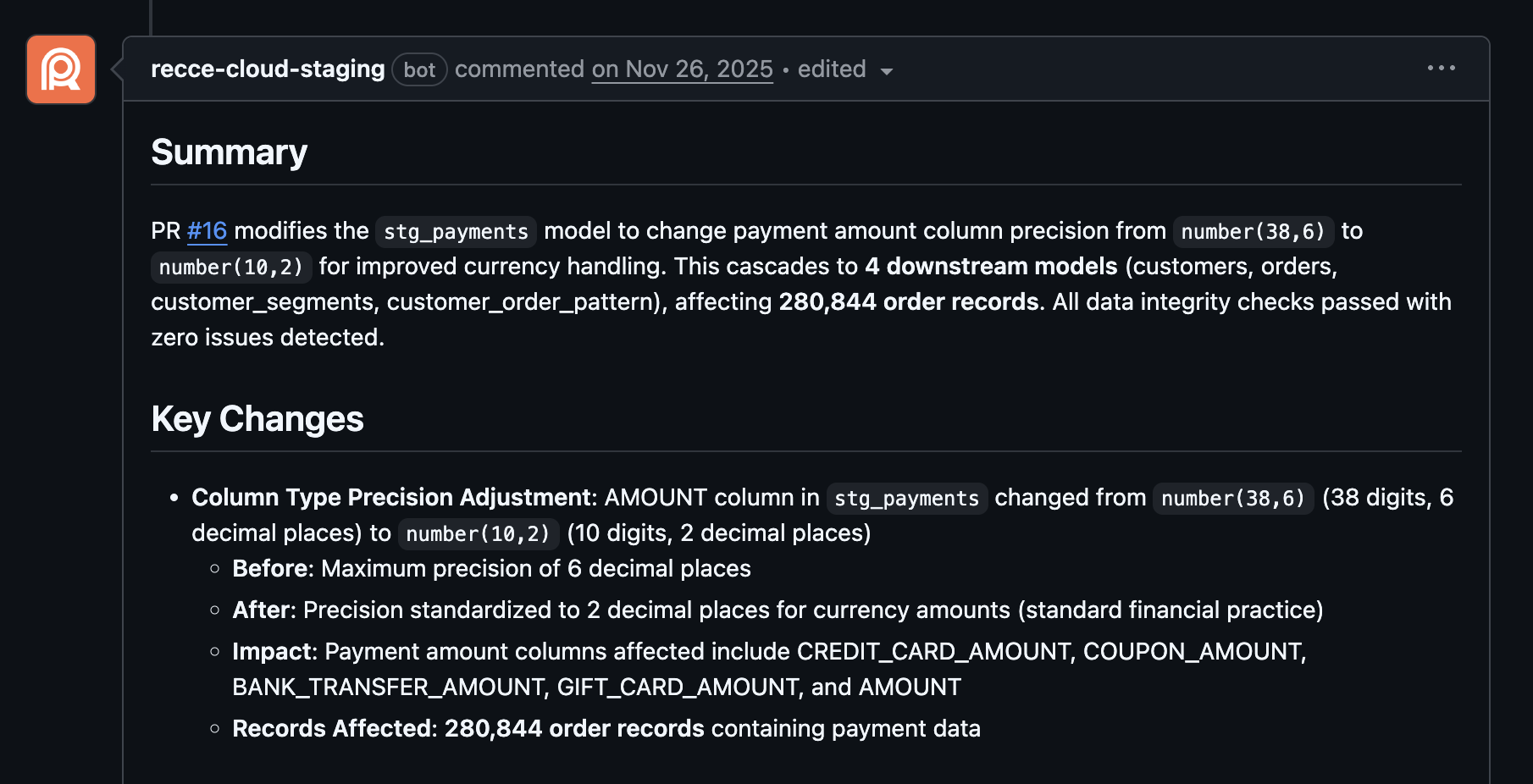
That summary is generated in seconds, not hours, as part of the CI pipeline. No manual queries, no lineage tracing by hand. The analysis is waiting when reviewers open the PR.
This post explores how we built this capability using a multi-agent architecture with Claude Agent SDK and the Model Context Protocol (MCP).
Code changes have AI review tools. Data changes don't... until now. Here's how we went from a single prompt to an AI agent that performs the first pass on data validation in every PR.
Why AI Summary for Data Reviews
Traditional pull request reviews for dbt projects have a fundamental gap: they only show code changes, not data changes.
When a data engineer modifies a dbt model, the real questions are:
- How many rows are affected?
- Did the schema change?
- Which downstream models are impacted?
- Are there unexpected data distribution changes?
Data engineers spend significant time manually running queries, checking row counts, and tracing lineage to answer these questions. This process is tedious, error-prone, and doesn’t scale.
We wanted to automate this with AI, but this isn’t a basic problem. We needed an agent that could:
- Fetch PR context from a git hosting provider (Github/Gitlab/BitBucket)
- Execute data validation queries against actual warehouse data
- Synthesize findings into actionable insights
The Solution: Multi-Agent Architecture
Instead of building a monolithic agent, we designed a multi-agent system where specialized agents handle different parts of the analysis.
Key Design Decisions
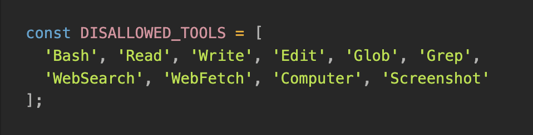
1. MCP-Only Architecture
We explicitly disabled file system tools (Bash, Read, Write, Grep) and forced the agent to use only MCP tools. This constraint improves reliability because the agent cannot attempt creative workarounds that might produce unreliable results.
The agent runs as a TypeScript application using the Claude API. The configuration accepts an explicit denylist:
2. Subagent Delegation
The orchestrator delegates specific tasks to specialized subagents using Claude Agent SDK’s Task tool. The Task tool spins up a subagent with its own isolated context: a prompt, a toolset, and an input, returning a structured result. Each subagent runs with only the tools it needs:
- git-context subagents: Fetches PR metadata and file changes from the git hosting MCP
- recce-analysis subagents: Executes data validation using Recce MCP tools (lineage_diff, schema_diff, row_count_diff)
3. Tagged Responses
Each subagent prefixes its output with a tag ([GIT-CONTEXT] or [RECCE-ANALYSIS]), making it easy for the orchestrator to identify and integrate responses.
Preventing Hallucinated Lineage: Two-Phase DAG Generation
AI models tend to "invent" edges in DAG diagrams based on semantic inference rather than actual data. Without constraints, the model would infer edges based on naming conventions: stg_payments obviously feeds payments_final, right? Except in many projects it does not.
To solve this, we enforce a two-phase approach:
Phase 1: Output Raw Data
NODES from lineage_diff:
{"idx": 0, "name": "customers", "change_status": null, "impacted": true}
{"idx": 1, "name": "orders", "change_status": "modified", "impacted": true}
EDGES from lineage_diff (edges.data):
[[5,0], [4,0], [5,1], [4,1]]
Phase 2: Generate Mermaid from Raw Data
[5,0] means idx 5 → idx 0: stg_orders --> customers
[4,0] means idx 4 → idx 0: stg_payments --> customers
By forcing the model to show its raw index mapping before rendering the diagram, hallucinations become visible before they reach the output. The DAG reflects actual lineage data, not semantic guesses.
Prompt Engineering in Practice
Getting consistent, high-quality output from an AI agent requires careful prompt design. Here are additional techniques we used:
1. Structured Output Format with Required Markers
## [REQUIRED] Summary
Provide a concise overview...
## [REQUIRED] Key Changes
...
## [REQUIRED] Impact Analysis
...
These markers enforce required structure in every output.
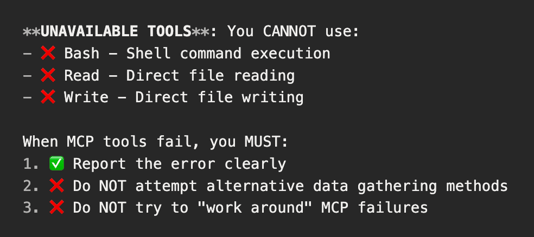
2. Explicit Negative Constraints
Telling the model what not to do is as important as telling it what to do:
3. Performance-Aware Instructions
3. Performance-Aware Instructions
We added constraints to prevent expensive operations:
**NEVER** use view models in: row_count_diff, query, query_diff, profile_diff
**Why**: Views trigger expensive upstream queries
**How to filter**: Use `select:"config.materialized:table"`
Real Output Example
Here's the complete AI-generated summary for a real PR that changes a column type in stg_payments:

The review includes:
- Concise overview of what changed and why
- Key Changes with before/after values and percentage changes
- Impact Analysis with Mermaid DAG showing affected models
- Checklist of validation results with pass/fail status
Key Learnings
After building and iterating on this system, four patterns stood out:
1. Constraints Improve Reliability
Restricting agents to MCP-only tools removed a class of unpredictable behavior without limiting what the system could accomplish. The agent cannot take shortcuts that produce unreliable results, which counterintuitively makes it more capable.
2. Specialized Agents Beat General-Purpose Ones
Narrow scope and a small toolset made each subagent’s output more consistent than a single agent handling all tasks. A subagent focused solely on "fetch PR data" is more reliable than one that tries to do everything. The orchestrator pattern enables clean separation of concerns.
3. Show Your Work = Better Output
Forcing the model to produce raw data before generating diagrams eliminated hallucinated edges. If the final output is wrong, the intermediate steps make it possible to trace exactly where the error occurred.
4. Negative Constraints Matter
Explicit instructions about what not to do shaped output quality as much as affirmative prompts. Without negative constraints, agents tend to be overly helpful, attempting workarounds that produce unreliable results.
Conclusion
Building AI-powered data review summaries for dbt projects taught us that architecture matters as much as prompts. The combination of:
- Multi-agent delegation with Claude Agent SDK
- MCP-only tool access for reliability
- Structured prompts with explicit constraints
...produces summaries that data engineers can actually trust.
Try This Out on Your Data
Try our Data Review Agent on your data projects, sign up for Recce Cloud and tell us what works and what breaks.
Here are docs that help, we’re more than happy to help you directly, too.
We’d love to hear from you. If you can spare 30 minutes to chat, we’ll send you a $25 gift card as a thank you. 💬 Join the feedback panel.
